SAPRFC
SAPRFC is an extension module for PHP 4 and 5, that makes it possible to call ABAP function modules running on a SAP R/3 system from PHP scripts.
I always wanted to test how SAP's remote function calls work together with PHP and since I am already evaluating CakePHP as our next development platform, I decided that the occasion was right to give it a try.
Next thing I did was to get my hands on The SAP Developer's Guide to PHP book by Craig S. Cmehil, which is an $85 cost and 98 page long (indexes included) tutorial on how to set up and use SAPRFC for PHP. Unfortunately the second chapter that discusses setting up your development system focuses mainly on Windows, so this post will contain the steps I took to set up SAPRFC for PHP on my x86_64 CentOS 5.4 server.
Package Requirements and Downloads
To get the latest PHP packages for Enterprise Linux I have used Remi's repository.
# wget http://download.fedora.redhat.com/pub/epel/5/x86_64/epel-release-5-3.noarch.rpm
# wget http://rpms.famillecollet.com/enterprise/remi-release-5.rpm
# rpm -Uvh remi-release-5*.rpm epel-release-5*.rpm
Remi's packages depend on the EPEL repository, so I am posting the installation procedure for EPEL as well. (if you haven't installed
it yet, now will be a good time to do so.)
In addition to any other PHP packages that your application requires, in order for the SAPRFC to compile correctly, you will also require the php-devel package.
Next thing is the SAPRFC package itself. The method to install it will be to build the saprfc extension as a dynamic module without rebuilding PHP. (Remi has already done that for us.) The package itself can be downloaded from here.
Continue by installing SAP's Non Unicode RFC SDK version 6.20 or 6.40. This must be downloaded directly from the SAP Service Support Portal. You will need a customer SAP support ID
Be advised however, that SAP has implemented some form of a DNS transparent cluster for their WEB service, so each time you log in there, you end up accessing a server with a different DNS name (something like https://websmp104.sap-ag.de/support). That means that your browser will not be able to store your credentials because every time you attempt to connect to https://service.sap.com/support, the DNS name changes so it pops up a dialog asking for login data again and again... Perhaps this is SAP's way of implementing the ultimate security system but, as far as I can say it is very annoying.
Anyway, once you are there select "Download" from the top menu. Next click "Search on all categories" from the left menu and enter RFC SDK on the search box that appears. You will be given the chance to select SAP RFC SDK 6.40 from the results page. Be careful not to choose the UNICODE version. Select Linux on x86_64 64bit from the list of architectures and you will end up with an SAR file in your download basket. Now you can download it
There is one more problem though. The file you download is of type SAR. meaning SAP Archive. In order to unpack it you will need SAPCAR, SAP's unpacking program. You download this the same way you downloaded RFCSDK -- just type SAPCAR on the search box. Only thing is that the Linux x86_64 version does not run on CentOS. You will need to download a Windows version, unpack the archive on a Windows machine and then upload it again on you Linux system. At least that is what I had to do. (From what I was able to understand SAP's SAPCAR for Linux is compiled to run under SuSE, so if you have satch a machine, you can try unpacking the archive over there...)
Installation
So now let's assume that you have placed SAP's RFC SDK under /opt/SAP/rfcsdk and SAPRFC extention module for PHP under /usr/src/saprfc-1.4.1/. Type the following commands on your shell prompt
or add them at the end of your startup file. (I put them in /etc/profile.)
# SAP RFC SDK
export SAPRFC_DIR=/opt/SAP/rfcsdk/
export PATH=$SAPRFC_DIR/bin:$PATH
If necessary, log out and back in again. Now move to the SAPRFC extension for PHP directory and issue the phpize command. This will create the configure script that needs to be run next. After configure completes, run make and make install (as root) to finish installation. When everything finishes the file saprfc.so will be placed in your /usr/lib64/php/modules folder.
Open you php.ini file located in /etc and add a line line
extension=saprfc.so
in the Dynamic Extensions section, save it, restart http server and you are ready to go.
[root@barbara ~]# service httpd restart
Stopping httpd: [ OK ]
Starting httpd: [ OK ]
Verification and testing
The very first check will be as simple as looking at the saprfc section of your phpinfo() page. You should be seeing something like :
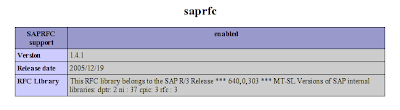
The next thing will be to write an actual program that does something more practical like connecting to an SAP R/3 system and fetching back some useful data. Since this already a rather lengthy post, I will prepare and provide a test program some time later.
One last comment: It took me a while to figure that out. All examples that come along with the SAPRFC module for PHP, as well as the examples on the "SAP Developer's Guide to PHP" book, use <? instead of <?php to introduce php code. This is going to give you a lot of trouble when attempting to use these files with php 5.3.1 so before trying anything else, go to the files in the installation directory -- especially saprfc.php that you will always include -- and perform the necessary changes.








